ByteFS File System
ByteFS is a file system built for byte-addressable SSD. Byte-addressable SSD is an idea inspired directly from at least 3 papers : Flatflash, 2B-SSD, and byte addressable file system such as NOVA, PMFS and EXT4.
I contributed and wrote codes in following aspects :
- Modifying BIO interface in linux kernel to fit our emulator interface.
- Add load to baseline file systems (PMFS, NOVA, F2FS, EXT4) to measure their performance.
- Metadata Cache.
- Page Cache (data cache).
This post contains 2 parts :
- Technical and high level insights into this project.
- My idea about my undergraduate research.
This post does NOT represent the viewpoint for my lab Platform X. It’s just an article to document what I learnt in my undergraduate research.
Why file system?
Modern development of file systems centers around existing file systems. From what I observed from code base PMFS, NOVA, SplitFS, EXT2, EXT3, EXT4, F2FS… they all build on pre-existing file systems.
I mean, why not? We use existing code that’s tested and structured as our code base. That’s normal, right?
From designing perpespective, I agree. But as an undergraduate student who just starts researching in this field, from implementation perspective, thinking about the concrete implementation while reading code is extremely toxic behavior. In the first 4 months, I can say, that I completely ignore the central idea, why file system?
When I looks at F2FS, I can see that, the design of the file system is determined by the underlying storage media. Because flash never overwrites stale data, it utilizes multi-head logging. Because NVMM has low latency on accessing memory, software overhead is non-trivial, hence the list structure and the radix tree in NOVA. Because 2B-SSD, essentially is SSD, with an internal logging and with byte-addressablity, EXT4, F2FS, NOVA, PMFS are all broken against new trade-offs and storage characteristics, hence our motivation of ByteFS.
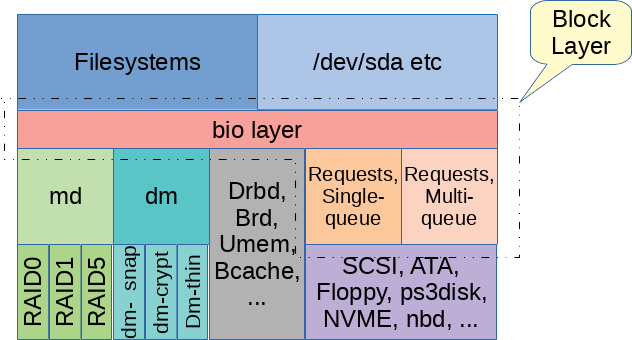
When I was messing with BIO interface. I read literally workqueues after workqueues, such as request_queue. Internally, when I was debugging our 2B SSD emulator, I also went through different queues and was thinking about solutions of optimization strategies by adding new queues. Queues and queuing policies are essential to control the traffics accross different path. Shortening the critical path is not only the job for the driver writer(like when I was tweaking the emulator), but also one of the most crucial thing to think about when we’re designing / implementing file system.
Without researching the characteristic of the storage media. You can’t write any code about the file system. Hence, I think I wasn’t qualified as a researcher at least for the first 4 months because I wasn’t thinking of the underlying storage media, our emulator for 2B-SSD(as a baseline, and we made corresponding changes to the interface) and I had no clue what we were trying to design for the file system.
Another important point is to think about different kinds of workload. This is learnt when I was under the task of testing all baselines as well as our file systems against different workloads like YCSB and filebench. There are meta-data heavy, data heavy workloads. There are workloads with different R/W ratio and file sizes. Thinking about the kind of workload Bytefs is good at and bad at takes tremendous time for me even when I wasn’t designing any features. It’s painful but that’s essentially the problems we have to deal with.
So, why file system? Essentially we try to execute read / write operations of a set of files. Why does this simple idea need 40k lines of code?
First, this isn’t true. PMFS only has ~6k lines of code, which is fairly light-weighted. With the journaling off (because 2B-SSD internally maintains a log), it’s ~3k lines of code. My mini file system (for one of my OS courses) is only 1.5k lines of code and it pretty much did everything a file system can do.
But one common problem these light-weighted file systems are :
- they are slow
- they are not sophisicated (don’t have certain functionalities such as mmap(DIO))
After 6 months, I could say that a file system accelerates generic file operations (read, write, mmap, …) and lowers the burden of storage media. Every design should aim to do these three objectives. Why three?
- Make it faster by caching and pure software strategies.
- Make it faster by lowering traffic in storage media critical path.
- Leverage the benefits for different file operations under different workload.
Why Byte FS?
The necessity to build a new file system is under lots of questions. Even NOVA, a very successful file system is still controversial.
We need to show it to people, that old file systems are unable to suit the new byte addressable SSD.
But is it true?
Actually it’s not ture. This makes ByteFS a hybrid of existing file system of byte addressable file system with block interface. But we have an internal log-maintained structure to guarantee consistency and to improve speed as well as lowering IO amplification, which makes it impossible to simply migrate to any existing byte-addressable file system, and it’s inherently against our motivation to use block-addressable file system like ext4 and f2fs. Although temporary they might out-perform many byte-addressable file system because their sophisticated software caching. In the long run, they will be replaced if Byte-addressable SSD becomes a trend.
This is why we build ByteFS, by modifying old byte addressable file system and to improve their performance and adapt them to byte-addressable SSD.
My Undergraduate Research
My undergraduate research starts from the 2nd semester as a junior student. The pressure is quite large as I have to finish my regular courses and be a course assitant holding lots of office hours while putting ~30 hours a week into this project.
I found a lot of things that can be improved during this time. Bytefs is not a project that goes smoothly and gives nice result immediately. I met and solved lots of problems as I was working my way out with 2 phD-candidate students.
I think I need to summarize them so when I continue my research, I can stop stepping into these traps again.
Communication
Among all the meetings I have with prof, only 0 meetings went very smoothly. Most of the time, 3 of us just seat in his office.
The implementation as well as the idea of the project got re-structured too many times.
One time we throw away a solution that’s been developed for 1 year.
Communication with prof. and your colleagues is extremely crucial because that’s like several layers of sanity check when you’re developing your project.
Planning and Thinking
The simplicity of a project & ideas are the most important thing after looking at all ideas that are popular.
If it’s complicated and hard to use your own words to explain it, you fucked up.
Planning after having a clear idea is very critical.
Don’t burn the midnight oil even when every one is pushing you.
If you’re 1 day away from deadline and you haven’t finished it, you fucked up.
Start summarizing your failure and try to finish it next time.
Measure : Engineering and Science
Get the data as fast as possible, because you’re not sure if this method works.
It’s not a project that must work out, so you need to find the probablity for you to get the number by getting a number as fast as possible.
Don’t build a project if there can be a project.
Use dirty means to acheive this if you can (Fake equivalent solutions). This is not faking data, it’s a sanity check.
Designs
Have a design before implementing it.
Tools and Setups
Write a script. Find a great setup or you need to write 10000 lines of code or spend 10 minutes every time you want to get a number.
Working with phds
Don’t trust seniors that easily. They are people and are prone to mistakes just like you.
Time commitment
Start early.
Scripts
Run YCSB (no cache)
#!/bin/bash
workloads=( "workloada" "workloadb" "workloadc" "workloadd" "workloade" "workloadf" )
output_folder="/home/h/output_nocache"
# iterate over the workloads until an unlogged workload is found
for workload in "${workloads[@]}"; do
log_file="$output_folder/$workload.log"
if ! [ -f "$log_file" ]; then
# the log file does not exist, this is an unlogged workload
touch "$log_file"
current_workload="$workload"
break
fi
done
# if no unlogged workload was found, exit with an error message
if [ -z "$current_workload" ]; then
echo "All workloads have already been logged."
exit 1
fi
echo "Running workload $current_workload"
mkfs.ext4 /dev/vdb && mount -t ext4 /dev/vdb dd/ && ./patch_filebench.sh
./Byte_fs/utils/ctrl 906 76800
cd ./YCSB
./bin/ycsb load rocksdb -s -P "workloads/$current_workload" -p rocksdb.dir=/mnt/h/dd -threads 100
cd ../
./Byte_fs/utils/ctrl 40
cd ./YCSB
./bin/ycsb run rocksdb -s -P "workloads/$current_workload" -p rocksdb.dir=/mnt/h/dd -threads 32 > "$output_folder/$current_workload.log"
echo "======================" >> "$output_folder/$current_workload.log"
cd ../
./Byte_fs/utils/ctrl 42 >> "$output_folder/$current_workload.log"
Run YCSB (with cache)
#!/bin/bash
if [ $# -ne 1 ]; then
echo "Usage: $0 <workload_name>"
exit 1
fi
workload="$1"
log_file="/home/h/output/$workload.log"
touch "/home/h/output/$workload.log"
mkfs.ext4 /dev/vdb && mount -t ext4 /dev/vdb dd/ && ./patch_filebench.sh
cd ./YCSB
./bin/ycsb load rocksdb -s -P "workloads/$workload" -p rocksdb.dir=/mnt/h/dd -threads 100
cd ../
./Byte_fs/utils/ctrl 40
cd ./YCSB
./bin/ycsb run rocksdb -s -P "workloads/$workload" -p rocksdb.dir=/mnt/h/dd -threads 32 > "/home/h/output/$workload.log"
echo "======================" >> "/home/h/output/$workload.log"
cd ../
./Byte_fs/utils/ctrl 42 >> "/home/h/output/$workload.log"
Patch filebench
echo 0 | sudo tee /proc/sys/kernel/randomize_va_space
Module install
make -j60 modules_install && make install
kernel config file is

Email : haor2@illinois.edu
Website : http://moomoohorse.com